cs231n Lec5
Introduction to Neural Networks
ConvNet 역사
-
1957: Frank Rosenblatt의 the Mark → Perceptron
-
1960: Widrow and Hoff의 Adaline and Madaline
-
1980: Fukushima의 Neurocognition
-
1986: back-propagation 최초로 소개됨
-
1988: LeCun의 Gradient-based learning으로 document recognition
-
2006: 딥러닝
-
2012: Speech recognition & Image classification
-
2012: Alec Krizhevsky의 Alexnet
Convnet의 total image

Input - low level features - mid level features - high level features - linearly spearable classifier
FC Layer: 프로세스 결과를 취하여 이미지를 정의된 라벨로 분류하는 데에 사용
- 즉, 공간 정보를 담은 이전 결과를 하나의 벡터값으로 나타내는 역할을 함
Convolution Layer: input image에 대해 filter를 slide하며 각 spatial location에서의 내적을 구해 특징을 뽑아냄 → activation map
- output size: (N - F) / stride + 1
- filter가 커지면 activation map은 조금 빨라지고, 그 크기가 작아짐 → sol) padding
Padding
- Output image size를 유지하기 위해 이용
- edge 성분도 활용할 수 있게 됨 → 패딩을 붙이기 전에는 가장자리의 픽셀 정보는 딱 한 번만 이용하게 되어 중요한 feature 정보가 있었다면 제대로된 CNN을 구현하지 못할 수도 있음
- output size: (N - F + 2P) / stride + 1
- map size를 동일하게 유지하기 위한 padding size = (F - 1) / 2
1x1 convolution: 1x1 size의 convolution filter를 이용한 Convolution Layer
- 채널 수 조절 가능
- 계산량의 감소
- 더 깊은 네트워크
- 비선형성을 더해줌
→ 모델 성능 상향
Pooling Layer: downsampling의 역할을 함
- CNN에는 많은 convolution layer를 쌓기 때문에 많은 파라미터가 필요한데, 이는 overfitting을 발생시킬 수 있음
- 이에 따라 downsampling이 필요한데 그 역할을 하는 것이 pooling layer
- 이미지의 차원은 줄이나, depth는 변하지 않음
- downsampling이 목적이므로 padding을 하지 않음
- Max Pooling: 필터 영역에서 max값만 뽑아 이용함
- Global Average Pooling: feature map 전체에 대해서 average pooling을 함 → feature를 1차원 벡터로 만드는 것이 목적
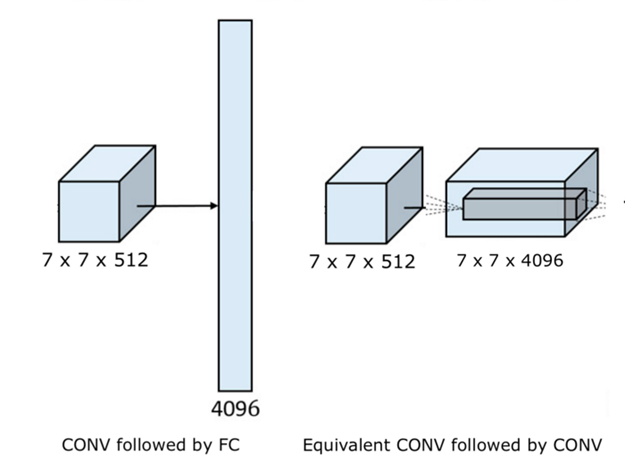
FC Layer: 이미지를 한 줄로 늘려 벡터로 만든 후 하나의 수를 추출해냄. 각 뉴런이 전체 입력 이미지를 한 번에 보는 것과 같음
Convolution Layer: 뉴런의 관점으로 봤을 때 local connectivity를 가진 뉴런과 같음. 입력 이미지를 부분부분 여러 번 보는 것과 같음
CNN Size 조절
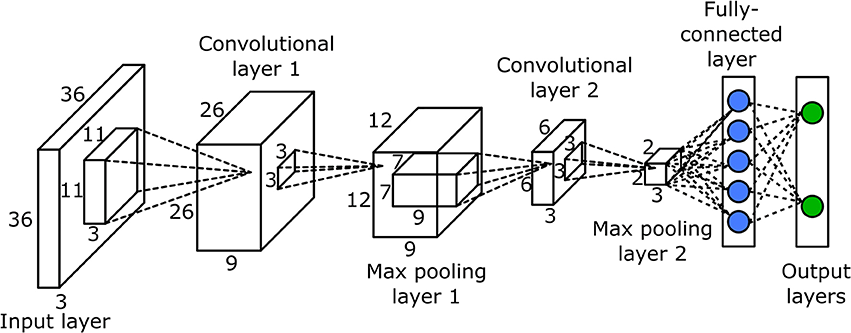
- Input layer: 2로 여러번 나눌 수 있어야 함
- Conv layer: 최대 5x5의 작은 필터, s = 1, l = O을 만드는 0 padding
- Pooling layer: (general) F = 2 or F = 3
CNN Architecutre
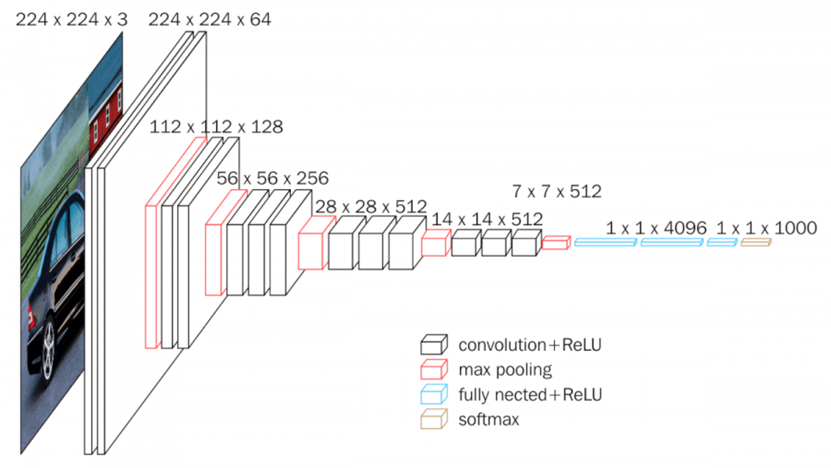
VGGNet: 네트워크의 깊이가 성능에 어떤 영향을 미치는지 확인하기 위해 만들어짐. 결론적으로, 네트워크의 깊이가 깊어질수록 분류 에러가 감소하여 성능이 좋아짐
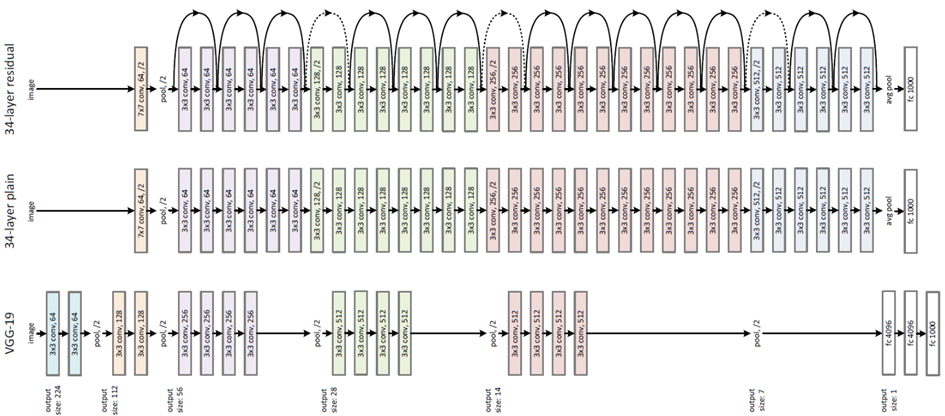
ResNet: Residual block 이용 → input을 output이 더해줄 수 있는 지름길을 하나 만들어줌. residual을 최소로 해주는 것이 목표
SENet: SE block 이용
- VGGNet, GoogLeNet, ResNet 등에 첨가하여 성능 향상 가능
- 목적: convolution을 통해 생성된 특성을 채널 당 중요도를 고려하여 재보정하는 것
- Conv 연산 뒤에 붙여 성능 향상 도모