Database Study Week4
섹션 5 - 좀더 복잡한 테이블간 관계 배우기
관계형 데이터베이스의 필요성
-
데이터에 중복된 정보가 있는 경우, 해당 데이터베이스에는 개선될 여지가 있는 것임
→ 중복된 정보가 있는 column을 따로 테이블로 빼서 테이블로 만드는 방식으로 개선 가능
-
관계형 데이터베이스를 사용할 경우, 유지보수가 편리하며 별도의 데이터임에도 이름이 같은 경우 등에 대해 중복 데이터가 아님을 알 수 있음
-
trade off: 직관적으로 데이터를 볼 수 없음
- MySQL의 경우, 테이블을 합쳐서 볼 수 있음!
Join
SELECT * FROM [table_name1] LEFT JOIN [table_name2] ON [table_name1].[table_name2_id] = [table_name2_id];]
합치려는 테이블의 id를 기준으로 table을 join
SELECT [column_names] FROM [table_name1] LEFT JOIN [table_name2] ON [table_name1].[table_name2_id] = [table_name2_id];]
표기할 column을 정해서 join
실습

모든 항목이 보이게 join

특정 항목만 보이게 join → error: id값이 중복으로 존재함

앞선 에러 해결 방안: 어떤 table의 id값을 보이게할 것인지 명시해주면 됨

topic table의 id column명을 topic_id로 변경
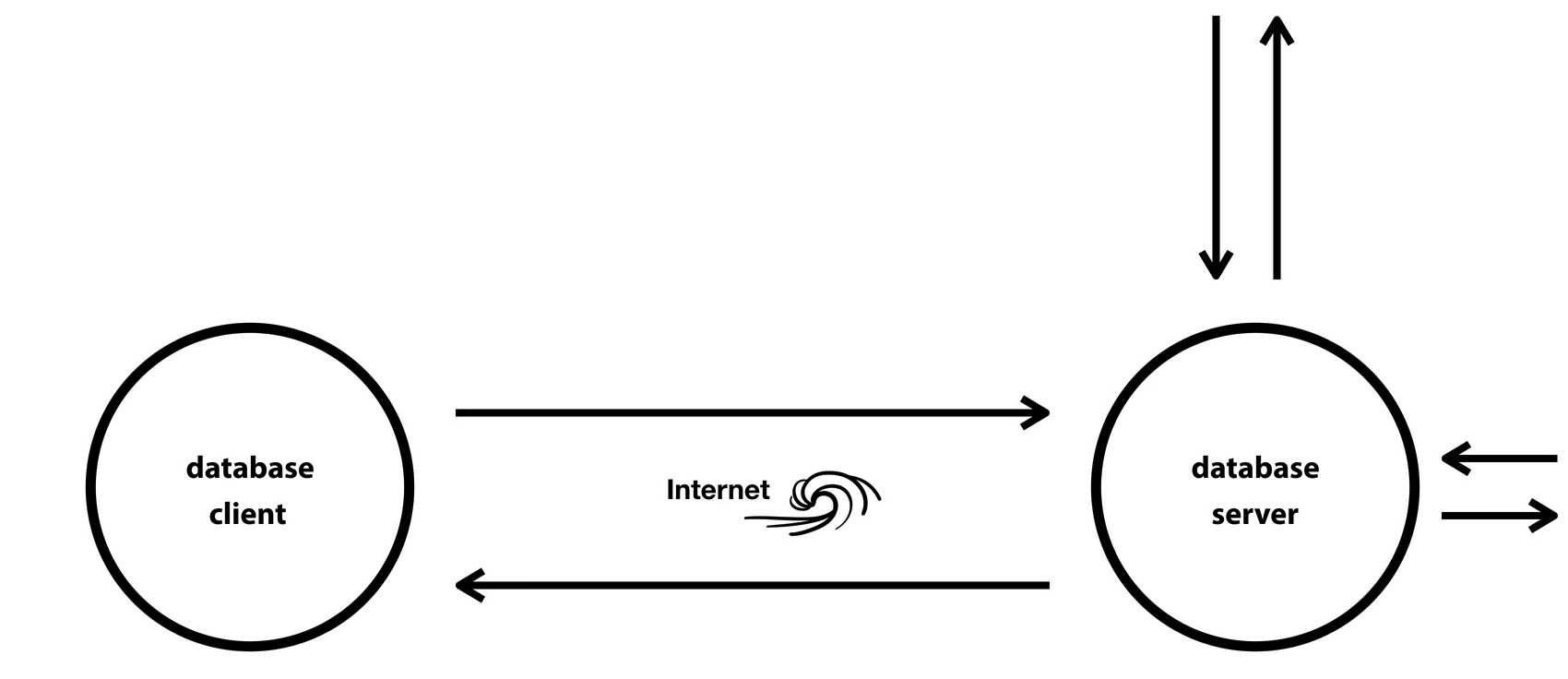
인터넷과 데이터베이스
database client와 database server가 인터넷을 통해 request, response를 주고 받음(정보 관리)
database client: request를 server에 보내는 쪽
database server: 들어온 request에 대한 response를 보내는 쪽
MySQL Client
- MySQL monitor: 명령어를 통해서만 제어할 수 있는 클라이언트
- MySQL Workbench: GUI를 이용해 간단히 제어할 수 있는 클라이언트
둘 모두 각각의 장단점이 있으므로 각자에게 맞는 클라이언트를 찾아서 사용하면 됨. 위의 두 클라이언트 외에도 다양한 클라이언트가 있으므로 찾아서 사용하기!
나의 경우, cmd로 주로 사용하기 때문에 cmd로 사용하는 것이 제일 편하다. github를 사용할 때에도 gitbash를 주로 사용하는데 이런 걸 보면 GUI 기반 프로그램을 사용하는 게 좀 낯선 것 같기도 하다. 사실 졸프하면서 fork라는 프로그램을 깔아봤는데 손이 잘 안 간다…